
Github
Web This release includes model weights and starting code for pre-trained and fine-tuned Llama language models ranging from 7B to 70B parameters. 26 2024 We added examples to showcase OctoAIs cloud APIs for Llama2 CodeLlama and LlamaGuard. . Web This repository contains an implementation of the LLaMA 2 Large Language Model Meta AI model a Generative Pretrained Transformer. We will use Python to write our script to set up and run the pipeline To install Python visit the Python..
WEB LLaMA-65B and 70B performs optimally when paired with a GPU that has a minimum of 40GB VRAM Suitable examples of GPUs for this model include the A100 40GB 2x3090. WEB A cpu at 45ts for example will probably not run 70b at 1ts More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x 4090 2x 24GB see here. WEB System could be built for about 9K from scratch with decent specs 1000w PS 2xA6000 96GB VRAM 128gb DDR4 ram AMD 5800X etc Its pricey GPU but 96GB VRAM would be. This repo contains GPTQ model files for Meta Llama 2s Llama 2 70B Multiple GPTQ parameter permutations are provided. WEB With Exllama as the loader and xformers enabled on oobabooga and a 4-bit quantized model llama-70b can run on 2x3090 48GB vram at full 4096 context length and do 7-10ts with the..

Medium
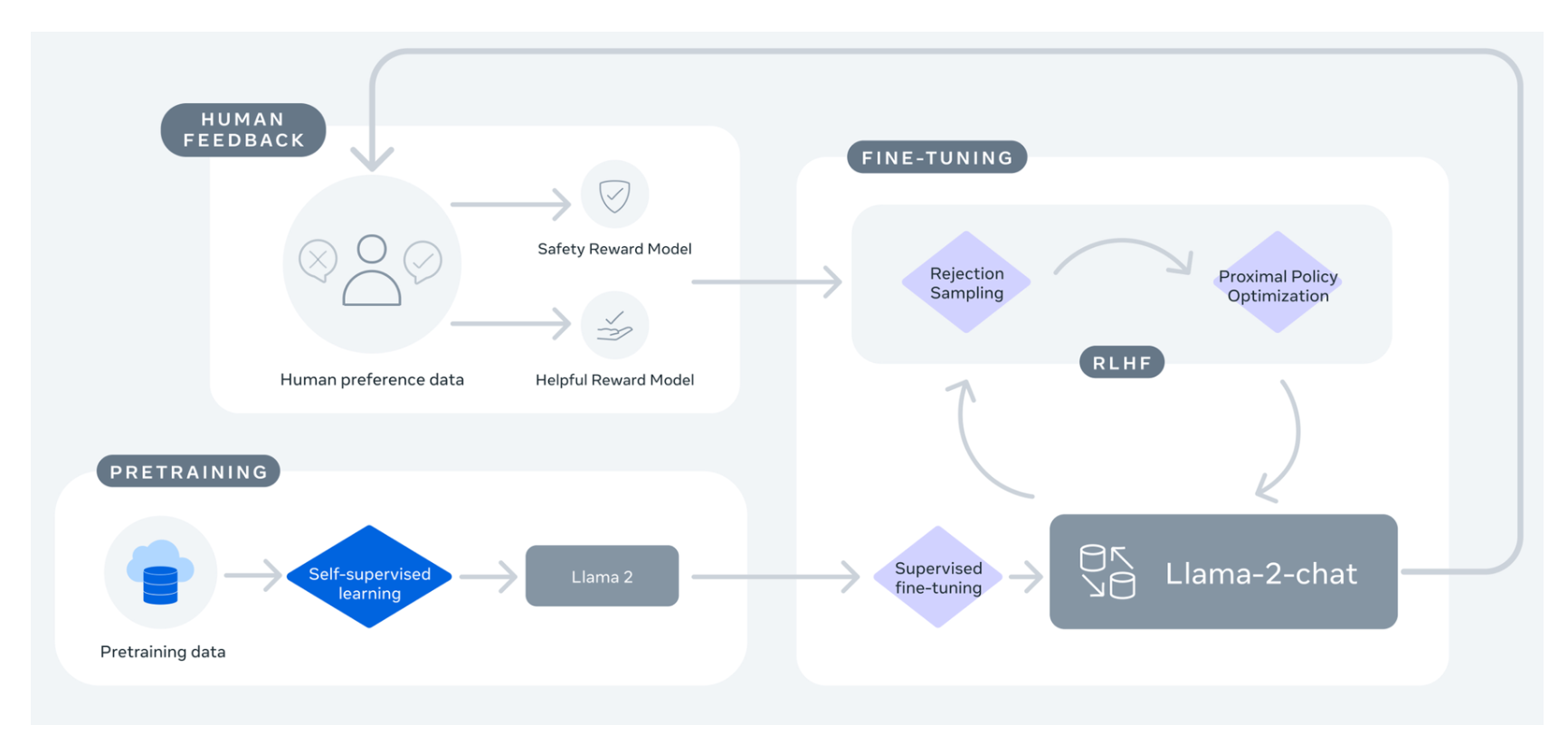
Llama 2 is broadly available to developers and licensees through a variety of hosting providers and on the Meta website Llama 2 is licensed under the Llama 2 Community License. This is a form to enable access to Llama 2 on Hugging Face after you have been granted access from Meta Please visit the Meta website and accept our license terms and acceptable use policy. Bigger models 70B use Grouped-Query Attention GQA for improved inference scalability Llama 2 was trained between January 2023 and July 2023. Agreement means the terms and conditions for use reproduction distribution and. We are releasing Code Llama 70B the largest and best-performing model in the Code Llama family..
We release Code Llama a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models infilling capabilities support for large input. We release Code Llama a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models infilling capabilities support for large input. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. We release Code Llama a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models infilling capabilities support for large input contexts and zero-shot. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters..




Komentar